Is more and bigger also better? Impact of dataset and model size in deep learning dose prediction
Joep van Genderingen,
The Netherlands
MO-0804
Abstract
Is more and bigger also better? Impact of dataset and model size in deep learning dose prediction
Authors: Joep van Genderingen1, Dan Nguyen2, Franziska Knuth1, Hazem Nomair1, Luca Incrocci1, Abdul Sharfo1, Uwe Oelfke3, Steve Jiang4, Linda Rossi1, Ben Heijmen1, Sebastiaan Breedveld1
1Erasmus MC Cancer Institute, University Medical Center Rotterdam, Department of Radiotherapy, Rotterdam, The Netherlands; 2UT Southwestern Medical Center, Medical Artificial Intelligence and Automation (MAIA) Laboratory, Department of Radiation Oncology, Dallas, USA; 3The Institute of Cancer Research and The Royal Marsden NHS Foundation Trust, Joint Department of Physics, London, United Kingdom; 4UT Southwestern Medical Center, Medical Artificial Intelligence and Automation (MAIA) Laboratory, Department of Radiation Oncology , Dallas, USA
Show Affiliations
Hide Affiliations
Purpose or Objective
Deep learning (DL) has demonstrated to be able to predict realistic 3D dose distributions. In this study, we investigate the impact of dataset and model on the quality of predicted dose distributions.
Material and Methods
The 745 included prostate cancer patients from the randomized HYpofractionated irradiation for PROstate cancer (HYPRO) trial were a mix of only prostate, prostate&vesicles (low dose to vesicles) and prostate&vesicles (high dose to vesicles). The patients were split into train/validation/test sets with n=561/75/109
In-house developed Hierarchically Dense U-Net (HDU) networks with 1.1 (HDUsmall) and with 3 (HDUlarge) million trainable parameters were trained for dose prediction. Both HDUs were trained with different subsets of the training set, n=56/140/280/561 (10/25/50/100% of total).
CT images with contours of PTVHigh, PTVLow, rectum, bladder, anus and femoral heads were used as input for the prediction models. The ground truth (GT) 23-beam IMRT plans were consistently generated with our in-house system for automated multi-criteria treatment planning, with 78 Gy prescribed dose to PTVHigh and 72.2 Gy to PTVLow. A 23-beam IMRT setup was used to avoid dosimetric bias from few-beam plans or VMAT segmentation.
The input dimensions were resampled to 256x256x64, reflecting a resolution of 1.92x1.65x4.66 mm3. The training was performed for 200 epochs on a 48 GB NVIDIA RTX 8000 GPU. HDUlarge was the largest model that could fit on the GPU.
Both for predictions and GT, all doses were normalized to PTVHigh V95%=99%. All dosimetric comparisons between prediction models and GT were performed with same set of test patients.
Results
Overall, all models showed a good performance for targets and organs at risk (OAR). The figure shows the absolute differences in dose metrics for the predicted dose distributions compared to the GT doses. In general, larger model (HDUlarge) and larger training set s decreased the differences with GT. However, more data did not necessarily compensate for choosing HDUsmall instead of HDUlarge (see e.g. Rectum V75Gy, Femoral Heads D0.03cc and Dmean).
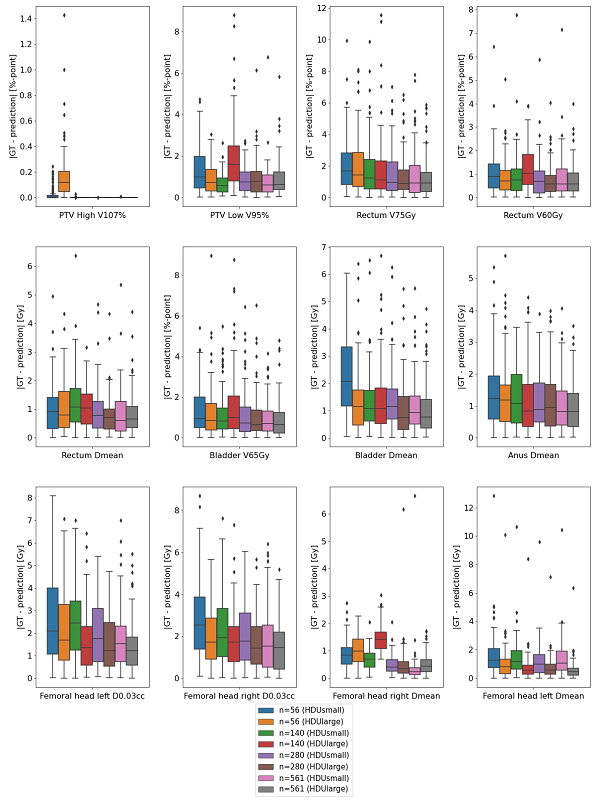
Conclusion
Using a large set of fully-automatically generated prostate cancer plans with consistent trade-offs, increasing the training set from 56, 140 to 561 patients only resulted in small reductions in differences between deep learning dose predictions and ground truth. Network was more important than dataset for reduction of these differences. As HDUlarge was the maximum that fits our GPU-card (which is the largest currently available), use of less memory-demanding network architectures could be explored to further improve deep learning dose prediction quality.